
The IaaS Provider With Highest Up Time: The Other Half Of The Story
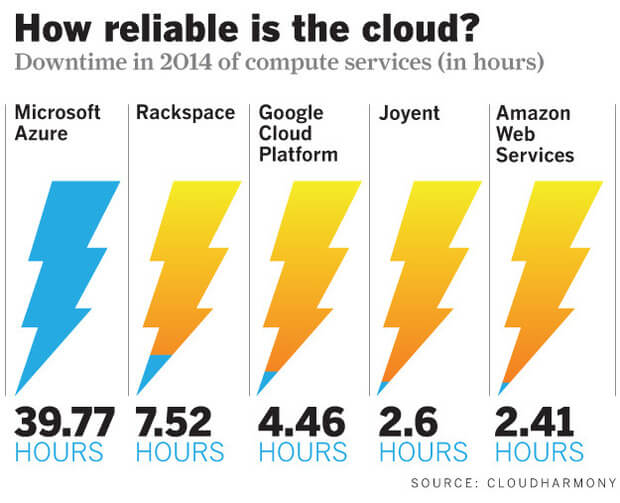
Brandon Butler of Network World is one of my favorite bloggers on cloud topics. His post comparing up time of the major cloud providers in 2014, highlights the CloudHarmony statistics comparing nearly every major provider. He gives a great non-biased presentation of the numbers, which speak for themselves.
CloudHarmony maintains a single web server in each region or availability zone for each provider and monitors it to record down time versus up time statistics. Clearly 2014 was a great year for AWS at the top with five 9s of overall availability with only 2.4 hours of downtime across its vast compute infrastructure.
These comparisons are very helpful for knowing which providers have their act together because the scarcity of failures is at least half of the high availability equation. But the studies done by CloudHarmony really don’t give the best picture of the other (and I believe more important) half of the equation: how possible it is to architect highly available applications on any given platform to ensure against inevitable failures.
Why do I think this half is more important? Because all of us who have been in IT for any amount of time know that there is simply no way to ensure a perfect environment that is completely free of failure. This is why the holy grail of availability is five 9s (99.999%) and not 100%. And any failure, no matter how rare, is long remembered. I can remember an IT mentor of mine telling me that one “Oh $#%!” wipes out a whole bunch of “addaboys”
If this is true, then the approach any reasonable person should take is to architect in such a way as to anticipate failure. To do this you need a specific set of tools:
- The ability to spread production workloads across geographic regions as well as across isolated availability zones within a region.
- The ability to establish replicated production data sets across multiple availability zones. This does not refer to backups or even to log shipping but to mirrored data sets that are available to your production application with automatic fail over in real time.
- Sophisticated monitoring of the health and utilization of assets.
- Sophisticated tools to spin up instances or added processing power to meet demand.
- Sophisticated tools to reroute traffic from unhealthy assets to functioning ones quickly without human intervention.
- The ability to automate snapshots of data sets and virtual machines as often as your business requires.
AWS has the best story to tell as of this writing with 11 geographic regions containing 28 availability zones, each of which represent a cluster of distinct data centers, and well over 55 additional edge locations. This massive infrastructure is all specifically designed for high availability architecture. On top of that vast physical footprint AWS has developed far and away the most robust tool set in each of the areas listed above based on a horizontal scaling philosophy that emphasizes redundancy and fault tolerance. For a detailed list of which tools are offered in which AWS region look here
Does your application require this kind of high availability? In most cases, no. Most companies can greatly improve their up time on any cloud platform if they consider their present self-hosted or collocated infrastructure’s up time record. But if up time is paramount to your business it’s nice to know where you can maximize it. The best way to maximize high availability is with a trusted AWS consulting partner familiar with the AWS tool set, who can architect well and keep up with the staggering pace with which AWS is innovating.
The competitive race has just begun among cloud IaaS providers and it is a marathon—not a sprint. AWS currently has a commanding lead in almost every respect, but Microsoft Azure and others are making massive investments and continue to innovate and add features. It’s an exciting trend and the benefits to customers will grow exponentially in the months and years ahead.
Blue Sentry is an advanced-tier Amazon Web Services (AWS) consulting partner specializing in application and data migrations, expert managed services and virtual desktops. Blue Sentry serves clients globally, with operations in North Carolina and South Carolina.