
A Well-Architected Operation Begins with the Right People

Achieving high availability, robust disaster recovery, agility and cost savings are all reasons to adopt a next-generation, automation-based approach to operations. This is what Blue Sentry Cloud’s managed “DevOps as a Service” is all about. We encourage our clients to restrict human access to production environments as much as possible, while establishing a unified change management process and automation pipeline in which all changes to production are done by machines. This process is essentially what is often referred to as a CI/CD change deployment pipeline based on an immutable artifact, and is the same for break fix, patches and updates, application feature changes, changes to infrastructure services, and any other change to production. At a high level it looks something like this:
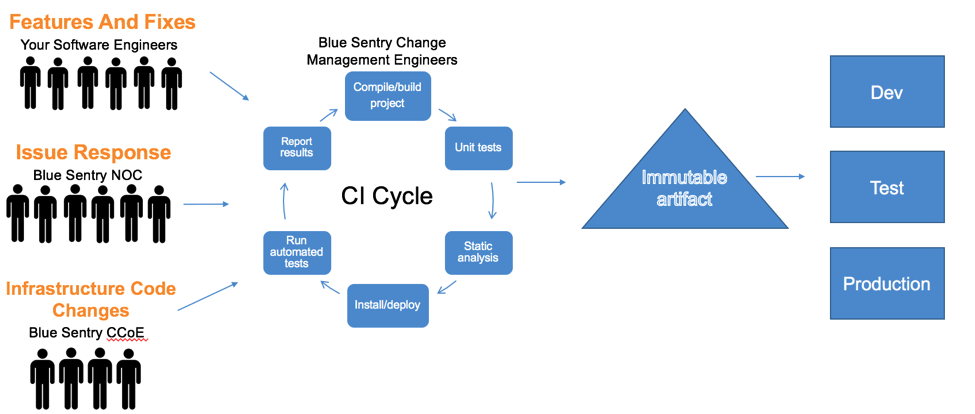
The Benefits:
The benefits to this approach are myriad, but a few are worth highlighting. First, service interruptions are greatly reduced as a result of the discipline that is required to operate this way. At Blue Sentry Cloud, for example, we operate with a double review pull request process for infrastructure code changes as part of our continuous integration cycle. This means that even if we are just changing a routing rule in a VPC, we edit the code, and have two senior DevOps engineers review the code, before it can be committed to the master repository.
Second, this approach prevents drift between what is actually in production and what is coded. This is an important benefit in a disaster recovery scenario since we depend on the infrastructure code to quickly re-create our production environments in another region, should the need arise. If our code does not faithfully represent the current state of production, our recovery time objectives can quickly become unrealistic.
Another great benefit that our clients enjoy is the reduced effort of compliance and audit. If we know all changes in production are made by this automated process, our change logs are a combination of code and machine logs. It’s that simple. This approach instills confidence in auditors and shortens audit times, and, more importantly, it gives us a more reliable security and governance outcome.
The Obstacles:
Of course, there are technical and automation hurdles to overcome. How will we aggregate and review our logs? What will our immutable artifact be? What is our automation and orchestration framework? What are the quality gates in our continuous integration cycle? These are all tactical problems that Blue Sentry Cloud solves for clients with custom solutions. A key strategic hurdle for technology and business leaders to be concerned with is what we call the People Perspective. Having the right people properly aligned around a unified operational vision is arguably more important than having the right processes and tools.
Traditional network operations center staff usually don’t have skills in code writing and may not understand nuanced architecture considerations related to infrastructure services in the cloud. So, how can we realistically expect them to be allowed to make changes to production only with code? Here are a few of the things we do at Blue Sentry for our internal Network Operations staff to address this problem:
- AWS training and certification.
- Training in specific tools and platforms such as coding in Terraform and using Packer to create artifacts
- Architectural showcases conducted by senior DevOps engineers with network operations center staff (sessions are recorded on video and archived for future reference).
- Code review showcases for environment architectures, conducted by senior DevOps engineers for the Network Operations Center staff. Like our Architectural showcases, these are videoed and recorded for future reference.
- A senior DevOps “buddy” is assigned to the Network Operations Center staff on a rotating basis for code editing support.
- Double review pull request process in which all code changes are reviewed by two senior DevOps engineers before they are committed to the master repository. This is possibly the best training of all—to learn by doing and having your work reviewed and corrected as necessary.
We have found that by hiring the right people, setting a clear vision of next-generation operational excellence, offering the support described above, and constantly pushing our team outside of their comfort zone, our team always has responded positively when we raise the operational bar. I know that, based on our experience, your enterprise can achieve this as well. Blue Sentry would love to help get you started on a foundation of best practice, and we wish you a well architected operation.