
High Availability Explained: Why AWS Beats Azure in Redundancy

I am often asked about High Availability on AWS. And we see a great deal of opportunity for users of AWS to improve in this area—so much so that it is a formal theme among our seven themes in the Cloud Maturity Index. It has become a major area of focus for Blue Sentry, because we have seen so many AWS users fail to take full advantage of what the platform offers in terms of redundancy.
Improvement begins with knowledge, and we think it is important to understand the architecture of the AWS infrastructure as a first step to utilizing the full High Availability tool set that AWS provides. So, let’s start with an understanding of AWS Regions. Many people hear the term region and they think “data center.” This would be accurate if you are talking about most cloud providers. On Microsoft Azure, for example, the U.S. East region is a single data center somewhere in the DC metro area. On AWS, there is a world of difference.
A region on AWS is comprised of Availability Zones, each of which is a cluster of data centers.
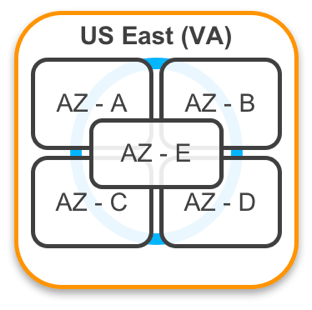
What is so special about Availability Zones? Well, that is the level at which AWS allows you to plan for redundancy. Each Availability Zone is a group of data centers that is:
- Located on a distinct flood plain from the other Availability Zones in the region
- Served by a public power utility distinct from power utilities serving other Availability Zones
- Connected to multiple Tier 1 transit providers for network redundancy
Perhaps the greatest thing about Availability Zones is the network connectivity that is built into the architecture. AWS has built 25 Tb/sec connectivity with very low latency among the data centers and availability zones within a region. This allows for extremely robust HA regimes at the application and data tiers of your workloads.
While AWS also uses this architecture to make its own services more redundant, we all know that “everything fails all the time.” As such, it is important to know that without the proper architecture, a workload is not highly redundant even if it is running on AWS. Many websites went down early in the year when S3 experienced an outage in U.S. East. While news reports spoke of this outage “breaking the internet,” no Blue Sentry Cloud clients were adversely affected.
Architecture is everything. I encourage you to take the Cloud Maturity Index for yourself. Assess your team’s maturity in the cloud. If you have HA concerns, do you have the skillsets to successfully implement your objectives? This is why Blue Sentry exists. We’d love to get you started on the right foot with best practices architecture and seed your team with the skills you need to operate with confidence.